The BSD Packet Filter: A New Architecture for User-level Packet Capture
The Network Tap
BPF有两个主要的概念
network tap
从网络设备驱动中收集packets的拷贝,并把他们出输给监听程序
packet filter
如果某个packet应当被接受,它将决定这个packet要复制多少份给监听的应用

图一 阐述了BPF接口的基本工作流程
当一个packed到达网络接口时,链路层的设备驱动通常会发送到系统协议栈中。
但是当BPF正在监听这个接口,这个需求将会先调用BPF。 用户定义的鼓励去确定是否一个包将被接受和每个包的多少字节应当被保存。对于每个接受packet的filter而言,BPF拷贝请求的大量数据给filter关联的buffer。然后设备驱动重新获得控制。
如果packet不是本地主机的地址,驱动将会返回一个中断。其他情况下,正常的协议处理机进程继续工作自从进程可能需要看一下在网络上的每个packet,并且在两个packed的间隔时间可能就few microsseconds ,这样的话就不可能对每个packet去触发一个系统调用read,BPF就必须在几个packet中间收集数据,并且当monitoring程序需要的read的时候返回。
To maintain packet boundaries,BPF encapsulate每个packet头中的一些数据,比如time stamp,length,and offsets for data alignment
Packet Filtering 由于网络监控器只是网络traffic中很小的一个部分,令人惊奇的性能优势在过滤不想要的interrupt context中的packets过程中得到了体现。
如何最小化的内存消耗是现代工作站中主要的瓶颈。packet should be filtered "in place"(eg where the network interface DMA engine put it) 而不是拷贝到其他的kernel buffer中区。因此如果packet被接受了,only those bytes that were needed by the filtering process are referenced by the host 相反的案例,SunOS 就是拷贝packet在filtering之前,这样直接导致性能下降。
(接下来就是SunOs STREAMS NIT机制的详细过程说明)
Tap Performance Measurements 在讨论packet filter细节之前,我们需要提出一些测量的指标。这些性能指标需要独立于packet filter机制。
我们配置了BPF 和NIT(上文所提及) 在SunOS内核4.1.1中,并运行在Sparcstation2 工作中中。the measurements reflect the overhead incurred during the interrupt prcocessing.(how long it takes each system to stash the packet into a buffer)。
对于BPF 我们简单地两区在调用bpf_tap()的前后的时间,使用Sparcstation的microsecond clock。对于NIT 我测量调用snit_intr()前后的时间并加上拷贝promiscuous packet到 mbufs的时间。
(promiscuous packet指的是那些没有本地主机地址的)。换句话说我们包含了NIT在适当地方拿取not filtering packets的细嫩那个干扰。为了获取精确的时间,在 instrumented code segments时,我们锁住了系统终端。
测试的数据集是一个处理不同packetlength的矩阵。我们约定处理每个packet使用2个配置,'accept all' filter,和 'reject all' filter
中间的实验对比 略过
The Filter Model 一个packet filter是一个返回简单的boolean的函数。true,则kernel 拷贝packet给app; false则忽略这个packet。
历史上有两种filter的抽象:
- 一个布尔值的表达式树(使用CSPF)
- 一个直接非循环的控制流图或CFG(第一次被NNStat使用,也被BPF使用)

例如,图四中的两种模型,识别网络上的 IP 或 ARP packet。
在树的模型中,每个节点代表一个boolean值,同时叶子节点代表一个packet field的测试predicate.边则表示操作运算符的关系。
在CFG模型中每个节点代表一个packet field predicate 并且 每个边代表控制传递。右边传递true,左边传递false。两个叶子节点表示整个filter的过滤结果。
这两个模型在计算层面而言是一样的,任何过滤器可以同时被两种方案表示。
但是在实现方面他们不一样, The tree model maps naturally into code for a stack machine while the CFG model maps naturally into code for a register machine。 大多数的现代机器都是基于寄存器的,随意我们任务cfg可以有一个更有效的实现。
CSPF(tree) Model
CSPF过滤引擎基于operand stack。指令push 常数或packet数据在栈中,并且执行一个二进制或位操作在顶部的两个元素。过滤程序顺序的执行指令的列表。最终,如果栈顶是一个非空值并且站空了那么packet久被接受,否则的话就拒绝。
这里有2个缺点在这种实现方法里面。
- 操作对象栈必须模仿
- 树的模型经常有多余的没必要的计算。
它的设计者还发现它还有一个问题,它不能解析变长的packet headers。(e.g., TCP headers encapsulated in a variable length IP header. Be- cause the CSPF instruction set didn’t include an indirection operator, only packet data at fixed offsets is accessible. Also, the CSPF model is restricted to a single sixteen bit data type which results in a doubling of the number of operations to manipulate 32 bit data such as Internet addresses or TCP se- quence numbers. Finally, the design does not permit access to the last byte of an odd-length packet.)
尽管它有很多缺点,但是它也提供了一个通用的packet filtering思想: 提供一个过滤机制的语言的解释程序在kernel中,提供一个良好过滤机制的描述和实现。自从CSPF看待packet是一个简单的byte array ,过滤模型就和protocol完全独立。(The application that specifies the filter is responsible for encoding the filter appropriately for the underlying net- work media and protocols.)
下一节描述BPF模型,
the BPF Model
BPF使用CFG过滤器模型,相对于树模型有一个显著的性能提升。尽管树模型可能需要多次冗余地解析数据包,但CFG模型允许将解析信息“内置”到流程图中。也就是说,图中的数据包解析状态是'记住'的,因为你知道你必须经过哪些路径才能到达特定的节点,并且一旦子表达式被评估,就不需要重新计算它,因为控制流图总是可以 (重新)组织,以便仅在遵循原始计算的节点上使用该值。
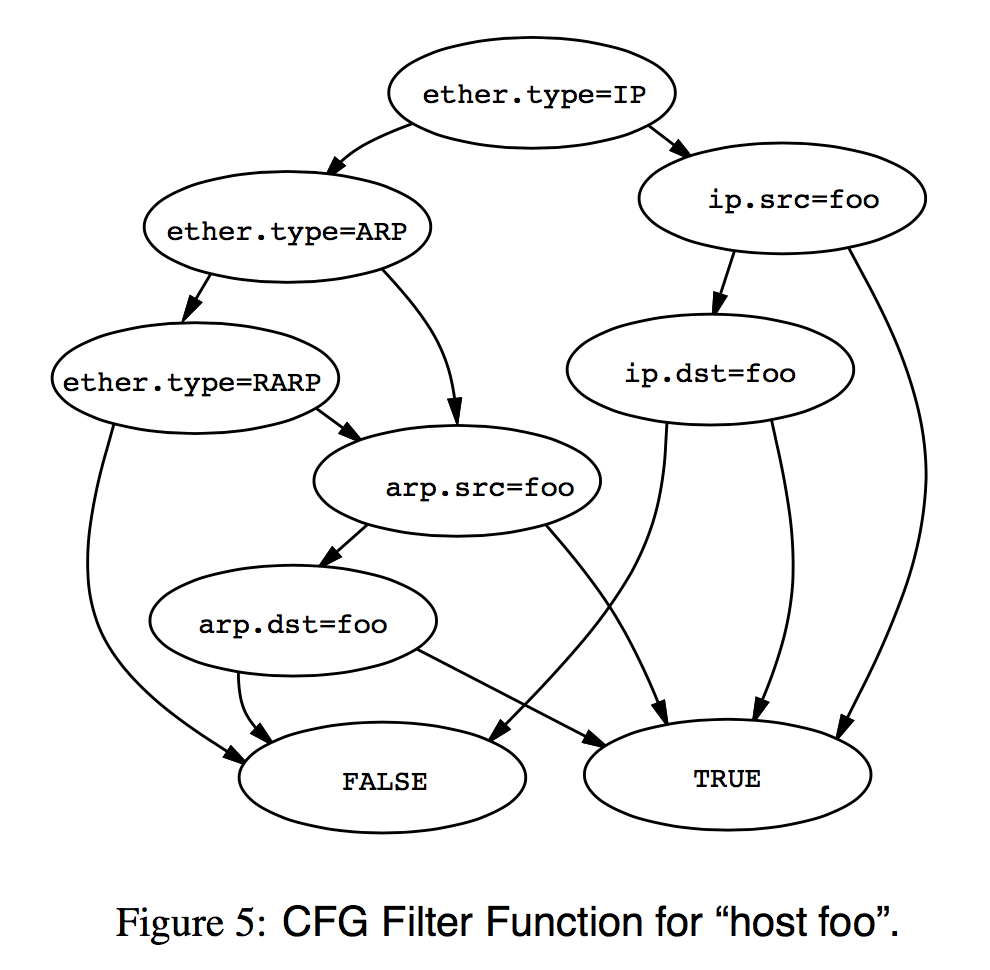
例如,图5展示了CFG filter function 接受所有来自网络地址 foo的 packets. 我们考虑网络层协议是IP,ARP和反向ARP的情况,所有这些都包含源和目标Internet地址。过滤器应该捕获所有的情况。相应地,首先测试链路层类型字段。在IP数据包的情况下,IP主机地址字段被查询,而在ARP数据包的情况下使用ARP地址字段。请注意,一旦我们知道该数据包是IP,我们就不需要检查它可能是ARP还是RARP。在表达式树模型中,如图6所示,遍历整个树需要七个比较谓词和六个布尔操作。通过CFG的最长路径有五个比较操作,平均比较次数为三次。

Design of filter pseudo-machine
使用CFG而不是树表达式作为 filter pseudo-machine的理论基础是实现高效的必要步骤,但是这样还不够。在借助 CSPF和NNStat的pseudo-machine 模型经验的公式,BPF模型也经历几代的(几年)设计和测试。我们相信当前的模型能够在不牺牲性能的前提下提供足够的通用性。它的演变受到下面几个设计约束的限制。
- 必须协议独立。内核不应该通过修改来适应新的协议支持。
- 必须通用。指令集应该足够丰富,遗嘱里不可预见的用途。
- Packet 数据引用必须最小
- 解码指令中必须包含单一的c语言开关语句
- abstract machine寄存器必须存储在物理寄存器中

图7是对应使用了BPF 指令集的 图5
The BPF Pseudo-Machine
BPF machine由 accumulator , index register , scratch memory store 和 implicit program counter组成,它们相关的操作可以分成下面几组
-
LOAD INSTRUCTIONS
将值复制到累加器或变址寄存器中。源可以是立即值,固定偏移量的数据包数据,可变偏移量的数据包数据,数据包长度或临时存储器。 -
STORE INSTRUCTIONS
将累加器或索引寄存器复制到暂存存储器中。 -
ALU INSTRUCTIONS
累加器使用索引寄存器或常量作为操作数。 -
BRANCH INSTRUCTIONS
根据常数或x寄存器与累加器之间的比较测试改变控制流程。 -
RETURNINSTRUCTIONS
终止封包,并指明要保存的数据包的哪一部分。如果过滤器返回0,则数据包完全被丢弃。 -
MISCELLANEOUS INSTRUCTIONS
目前是 register transfer instructions
指令格式的定义如下
---------------------------
| opcode:16 | jt:8 | jf:8 |
---------------------------
| k:32 |
---------------------------
opcode 去顶指令和取址模式
jt 和 jf 用来进行条件跳转,t ture, f false
k是用于各种目的的通用字段
详细的指令集 见下表

寻址模式 见下表

Examples
//filter accepts all IP packets
ldh [12]
jeq #ETHERTYPE_IP, L1, L2
L1: ret #TRUE
L2: ret #0
//accepts all ip packages except ,128.3.112 or 128.3.254
//mask=24
ldh [12]
jeq #ETHERTYPE_IP, L1, L4
L1: ld [26]
and #0xffffff00
jeq #0x80037000, L4, L2
L2: jeq #0x8003fe00, L4, L3
L3: ret #TRUE
L4: ret #0
其中 #0x80037000 和 #0x8003fe00 就是对应的ip地址
Parsing Packet Headers
上面是在假定了数据在packet固定的位置中,但是事实上TCP header是需要根据IP header来计算的。
ldb [14]
and #0xf
lsh #2
一旦IP头的长度算出来,那么TCP section可以被直接访问。
Note that the effective offset has three components.
- ip header length
- the link level header length
- the data offset relative to the TCP header
假设部分数据 代码如下
ldb [14]
and #0xf
lsh #2
tax
ldh [x + 16]
jeq #N, L1, L2
L1: ret #TRUE
L2: ret #0
由于IP报头长度计算是一种常见的操作,因此引入了4 *([k]&0xf)寻址模式。用ldx指令代替将过滤器简化为:
ldx 4*([14]&0xf)
ldh [x + 16]
jeq #N, L1, L2
L1: ret #TRUE
L2: ret #0
上面的代码我们已经假设了数据是tcp/ip header,现实情况下我们还需要检测 link layer type 是 IP, IP protocol type是 TCP 。并且TCP Header 只有第一个fragment包含,其他的包含第一个之后的fragment都会被拒绝。
ldh [12]
jeq #ETHERPROTO_IP, L1, L2
L1: ldb [23]
jeq #IPPROTO_TCP, L2, L5
L2: ldh [20]
jset #0x1fff, L5, L3
L3: ldx 4*([14]&0xf)
ldh [x + 16]
jeq #N, L1, L2
L4: ret #TRUE
L5: ret #0
Filter Performance Measurements
略
应用
tcpdump